Introduction
To the domain expert (e.g. Computer-Assisted Interventions researcher)
Are you tired of not optimizing your neural network architecture yourself? Are you just using the currently hot architecture, despite not knowing if it is really the best architecture for your problem or if some change might improve the results?
With AutoSNAP we introduce a method that addresses exactly this challenge. Instead of trying and optimizing an architecture yourself, you let an AI do the work – AutoSNAP works in a reasonable runtime (4 GPU days) and is very reliable at finding a very well-performing architecture.
To the learning expert
Have you played with Neural Architecture Search, but find the search time of “discrete approaches” (like NASNet) forbidding? Have you tried using “continuous approaches” (weight-sharing), but did not observe the architecture translated when discretizing it?
We present a novel method that – like NASNet – tests discrete architectures in a test environment while at the same time achieving good results in reasonable search time.
How we discovered LEARNING FOR LEARNING (=To US)
We were searching for patterns between architecture/block design and robustness to adversarial examples… but alas, adversarial examples do not seem to be an artifact of block design. However, our methodology showed parallels to emerging Neural Architecture Search work. Seizing the opportunity, we translated our work to performance over robustness.
In consequence, following our i3PosNet work, we set out to improve the Deep Learning aspects of instrument pose estimation. Creating a method for the job that was previously the students: coming up with a suitable network architecture our task: Let’s train a network for that…
Video presentation
Paper
Kügler, D*; Uecker, M*; Kuijper, A; Mukhopadhyay, A (2020): AutoSNAP: Automatically Learning Neural Architectures for Instrument Pose Estimation. Accepted at MICCAI 2020. arxiv.org/2006.14858
*Equal contribution
AutoSNAP: Automatically Learning Architectures for Instrument Pose Estimation
The ideas
Architecture representation
We wanted to investigate patterns in the relationships between architecture block designs (think ResNet-block, DenseNet-block) and a performance criteria (think F1-score, robostness to adversarials). So we needed a representation (i.e. description language) to describe blocks in a way that
- we could understand
- the machine could understand
- describes topology
- specifies “neural/node operations”
- is flexible
- is powerful
- is pretty unambiguous (i.e. we could easily identify identical blocks)
- is simple (because that is always better)
At this point, we take a short look at how the related work has addressed this challenge.
NASNet representation
Most prominently, NASNet and its derivatives stack NAS units (see Figure), which feature 5 parameters: 2x layer operations (yellow), 1x merge operation (green) and 2x index of input to the layer operations (“layer A” and “layer B”). Internally, these are represented as classes.
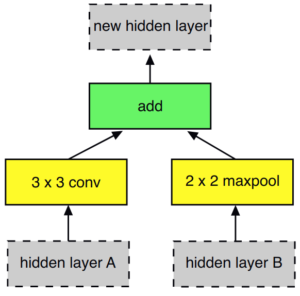
We identified several issues with this “representation”: indexing operations have no consistent “meaning” associated, the design favors flat architectures and extreme redundancy (many representations could lead to the same actual architecture).
DARTS Representation
The continuous architecture search paradigm introduced by DARTS (Liu et al., 2019) works the idea that you can do all architecture options at once, but throw away less successful options.
In the implementation, this is done by applying all operation options in parallel and calculating a weighted sum over them. The optimization alternates between layer-weight and sum-weight optimization. The “throwing away” translates to removing the sum and just using the highest weighted operation.
AutoSNAP representation: SNAP
We settled for one of the simplest representations possible: A string of symbols, where every symbol represents an operation on a stack of tensors. Our Symbolic Neural Architecture Patterns have symbols for “layer operations” and topological operations in effect fulfilling the challenges posted above.
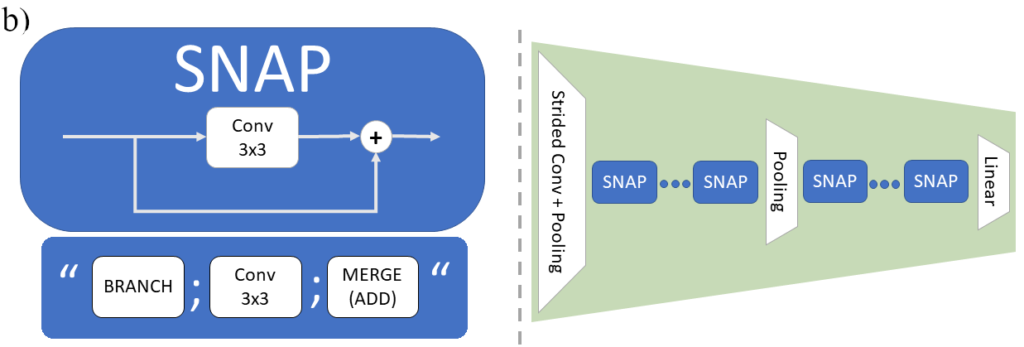
As is common for language processing, symbols can be encoded in a one-hot vector and processed using Recurrent Neural Networks independent of string length (up to a maximum length). Importantly, they can be translated into a latent space (representing the whole SNAP, i.e. architecture, in one vector) using an auto-encoder.
Search
The second question is how to get better architectures. Since we came at this question wanting to understand robustness, we started with just estimating the performance. We hoped to find some patterns in the SNAP, which we could then test rigorously for robustness.
Changing to neural architecture search, there was no real correlation between the latent space and the performance of the corresponding architecture. So we wanted to enforce a correspondence there, i.e. if we found a well-performing architecture in latent space, we could find other well-performing architectures around it. We implemented this by adding a single-layer performance prediction layer to predict performance from the latent space (single layer means we are forcing a linear relationship and therefore correlation). We added some more losses to make the problem more robust and stable (see the paper for details).
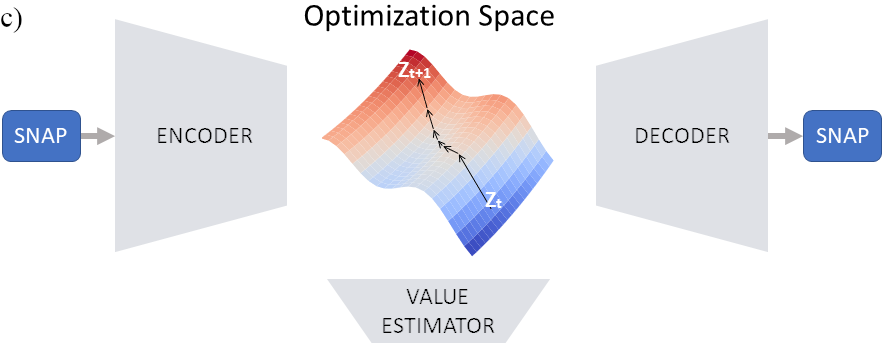
Finally, improving architectures: well the solution here is pretty straight-forward. We have a differentiable relationship between latent space and performance, we can do gradient search. This is similar to the solution of Luo et al. (2018) with the difference, that our latent space represents the full block, whereas in their solution they create an independent latent space per “NAS unit” (so their representation is also different, see above).
Results
Please refer to our paper for quantitative results.
Code
We are still working on cleaning up the code. Follow me on twitter to get updates on this.
Supplementary Document
References
Since this blog post is only an introduction to the paper, this references is as short as possible.
- Zoph et al., 2017: Learning Transferable Architectures for Scalable Image Recognition. CVPR 2018. arxiv/1707.07012
- Liu et al., 2019: DARTS: Differentiable Architecture Search. ICML 2019. arxiv/1707.07012
- Luo et al., 2018: Neural Architecture Optimization. NeurIPS 2018. arxiv/1808.07233